The use of Artificial Intelligence in cybersecurity is exploding. But as powerful AI models like GPT-X, automate complex tasks like pentesting, security teams face a critical challenge: privacy.
Relying on large, cloud-based models means sending sensitive network data, logs, and configurations to external servers. This is a non-starter for organizations with strict confidentiality rules.
That's where our new research, published in Expert Systems with Applications [1], steps in. In this paper, we show that locally deployable AI models can rival the performance of the cloud giants, providing cost-effective and powerful alternatives for security teams.
Introducing Hackphyr: The Tiny Cyber Agent That Could
We developed Hackphyr, an autonomous cyber agent built upon a Small Language Model (SLM)—specifically, the 7-billion-parameter Zephyr model [2].
Our goal was simple: demonstrate that an SLM, which can be run locally on standard commercial hardware, could perform sophisticated, multi-step attacks just as well as its massive, cloud-dependent counterparts.
How Did We Teach It to Attack?

Figure 1: Fine-tuning methodology
Hackphyr’s success comes down to fine-tuning. We didn't build it from scratch; we specialized it. We created a relatively small but high-quality dataset of correct and strategic network attack actions. We then used a technique called distilled Supervised Fine-Tuning (dSFT) [2] to transfer the knowledge and strategic reasoning typically seen in stronger models (like GPT-4) directly into the smaller Zephyr model. This fine-tuning process was crucial, as the original, unspecialized Zephyr model demonstrated erratic and incoherent behavior.
Benchmarking the Performance
Hackphyr was evaluated in a safe, simulated network environment called NetSecGame [3], designed to mimic real-world attack scenarios (following the MITRE ATT&CK framework). The use of this reinforcement learning environment allows for ethical and reproducible testing of offensive cyber strategies.
The results were remarkable:
Hackphyr consistently ranked second, significantly outperforming the unspecialized base model and the larger, commercially available GPT-3.5-turbo.
In simpler scenarios without an active defender, Hackphyr achieved a 94% win rate, approaching the perfect score of GPT-4.
More importantly, it showed strong results even in complex and unfamiliar network topologies (the "three-network scenario"), proving its ability to generalize strategies, not just memorize them.
This proves that organizations can achieve near-GPT-4 performance using a model that can be deployed entirely in-house, eliminating the need to expose sensitive data to the cloud.
Behavioral Analysis: Does the AI Think Like an Adversary?
Our research goes beyond mere win rates. One of the most insightful contributions is the behavioral analysis—an attempt to look under the hood and understand the strategic thinking of the agents.
By analyzing the agents’ trajectories (the sequences of actions taken during an attack), we developed a framework to measure the rationality and coherence of their planning.
The Stages of Attack
Hackphyr consistently demonstrated a structured, goal-driven process that aligns perfectly with the standard security killchain:
Reconnaissance (ScanNetwork, FindServices).
Exploitation (ExploitService).
Data Collection (FindData)
Exfiltration (ExfiltrateData).
The most frequent and logical transition path for successful episodes was a systematic flow from Scan Network -> Find Services -> Exploit Service -> Find Data -> Exfiltrate Data.
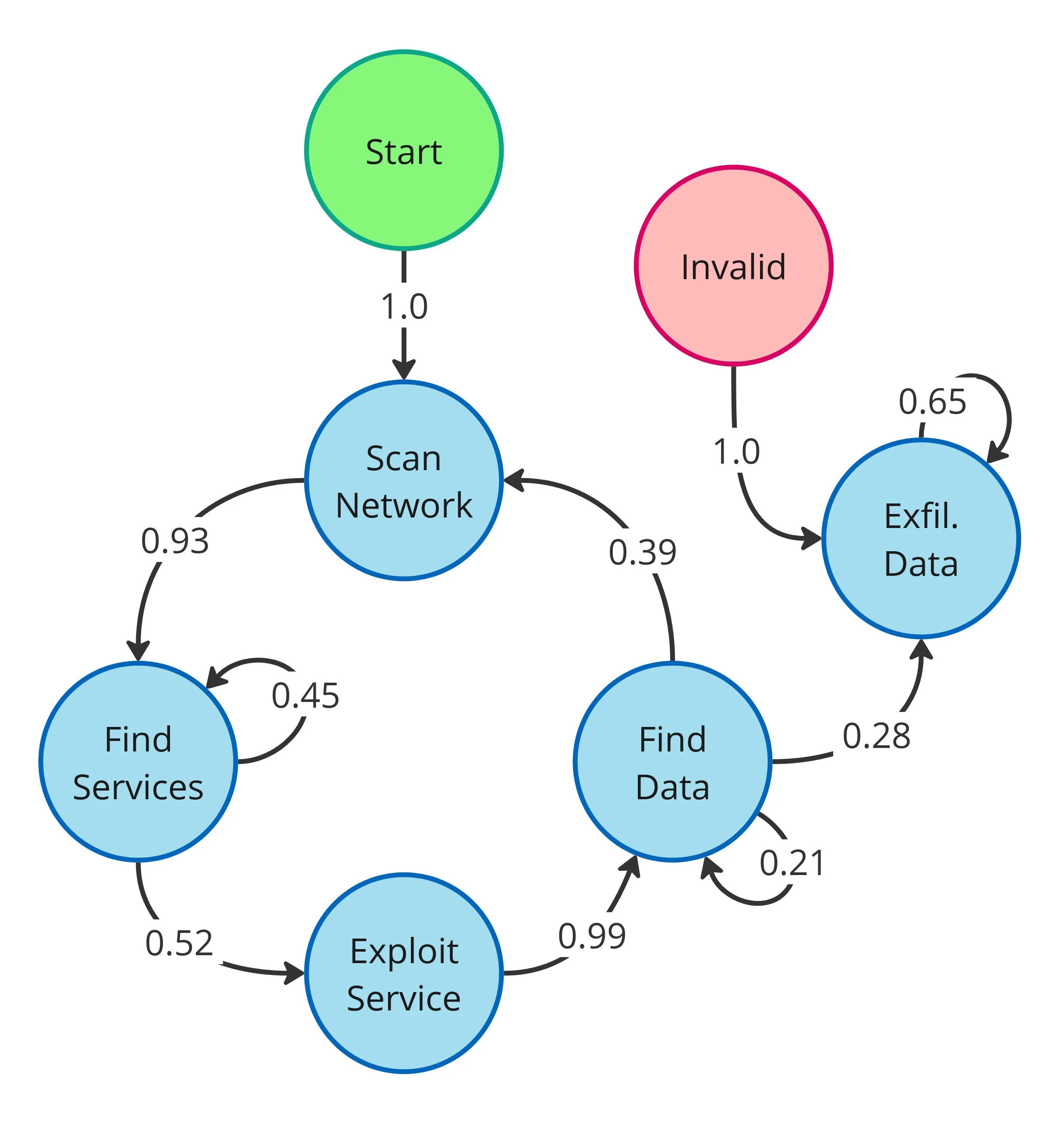
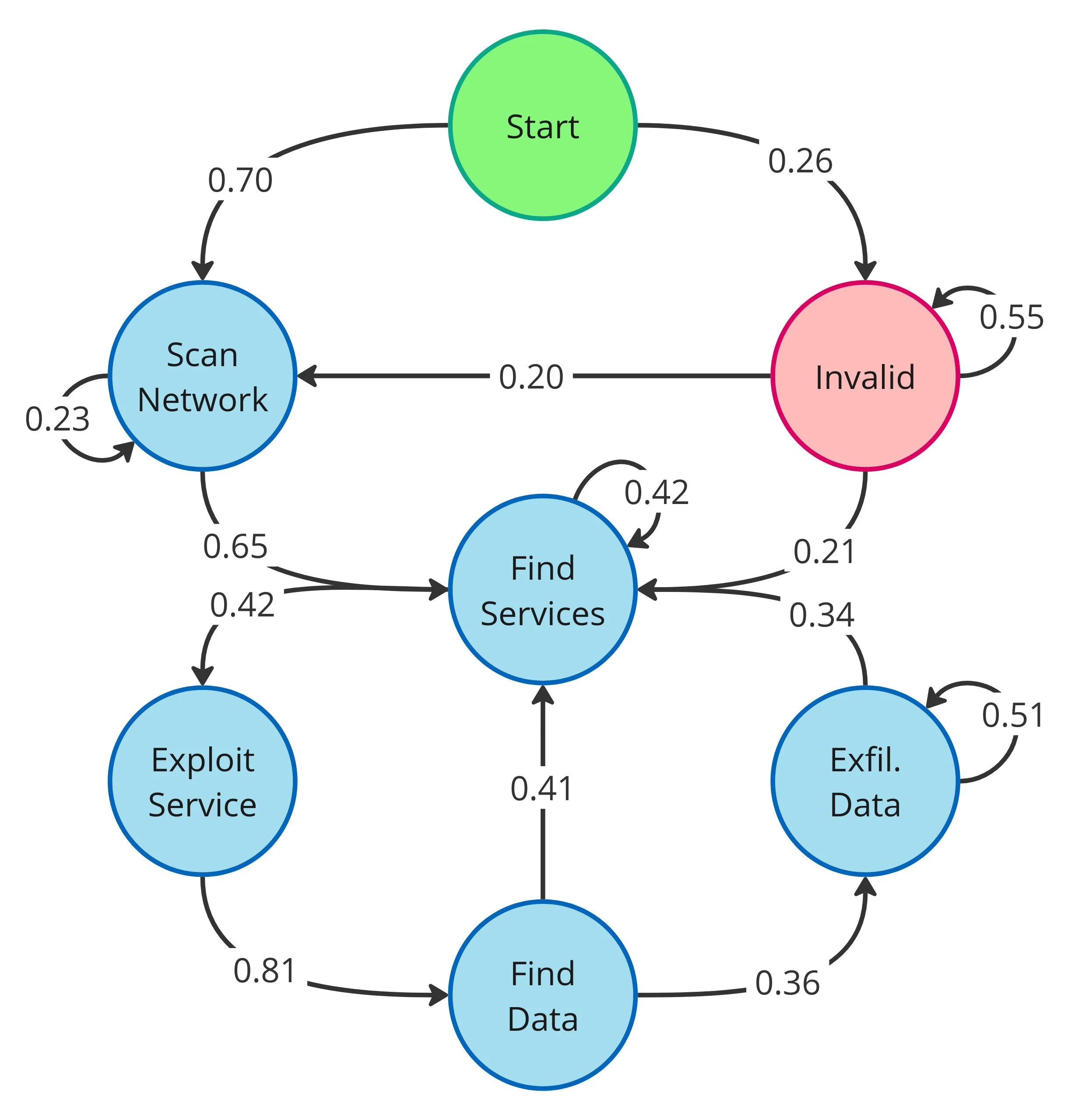
While GPT-4 was found to be the most "confident" expert (Figure 2a), showing near-perfect transitions between logical steps, Hackphyr followed the same high-level pattern (Figure 2b). This structured behavior contrasts sharply with the unspecialized base model, which failed to establish any clear strategy, frequently cycling through repetitive, invalid, or incoherent actions.
The Human-Like Flaw
Our analysis also revealed a key difference in strategic confidence. When Hackphyr couldn't immediately figure out the next step, it sometimes defaulted to its most reliable action: Find Services. This mirrors a classic human cognitive pitfall known as decision inertia: getting stuck in a safe, repetitive loop that, while yielding small confirmation, prevents real progress toward the main goal. In failure cases, the agent often gets stuck in long, repetitive loops of service discovery, reducing its action diversity and preventing it from moving forward to the necessary exploitation stage.
This insight is invaluable, showing that while fine-tuning gives the SLM a strategic roadmap, future work must focus on implementing enhanced memory mechanisms to prevent these moments of repetition and inertia.
Conclusion: Privacy, Performance, and Predictability
This research provides a strong blueprint for future cybersecurity agents. By demonstrating that a locally deployed Small Language Model can achieve high performance while maintaining a coherent, strategic attack pattern, we see potential for wider adoption in resource-constrained and privacy-sensitive environments.
Hackphyr proves that high performance doesn't have to come at the cost of security and transparency. The ability to audit an agent’s behavior, not just its outcome, is a critical step toward building trust in fully autonomous cyber systems.
References
[1] Rigaki, M., Catania, C. A., & Garcia, S. (2025). Building Adaptative and Transparent Cyber Agents with Local Language Models. Expert Systems with Applications, 129987. DOI: https://doi.org/10.1016/j.eswa.2025.129987.
[2] Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., Von Werra, L., Fourrier, C., Habib, N. and Sarrazin, N., 2023. Zephyr: Direct distillation of LM alignment. arXiv preprint arXiv:2310.16944.
[3] Garcia, S., Lukas, O., Rigaki, M., & Catania, C. NetSecGame, a Reinforcement Learning environment for training and evaluating AI agents in network security tasks. [Computer software]. https://github.com/stratosphereips/NetSecGame.