


Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
Two years ago, we launched the “Introduction to Security” class as a Massive Open Online Course with one ambitious goal: to make high-quality, hands-on cybersecurity education free and accessible worldwide. The response has been really beyond anything we imagined.
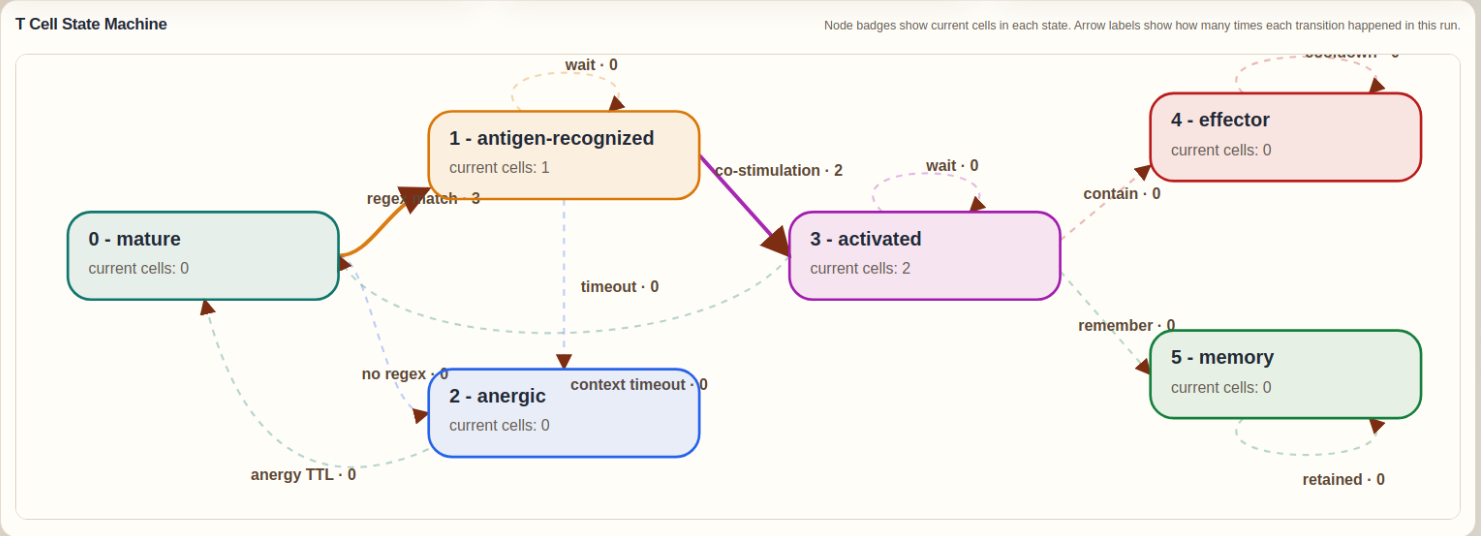
The T Cell module was created to give Slips a stateful adaptive response layer on top of its existing evidence pipeline. While the original detectors already provide the innate immune component through PAMP and DAMP evidence, the T Cell module adds antigen recognition, co-stimulation, context evaluation, tolerance, activation, effector action, and memory. It does this by extracting structured antigens from live evidence, matching them against the accepted regex repertoire generated by RegexGenerator, and then combining that recognition with the cumulative danger signaled by recent PAMP and DAMP observations. This allows Slips to move from isolated detections to a more explicit immune decision process that can decide when to ignore, when to contain, and when to remember.
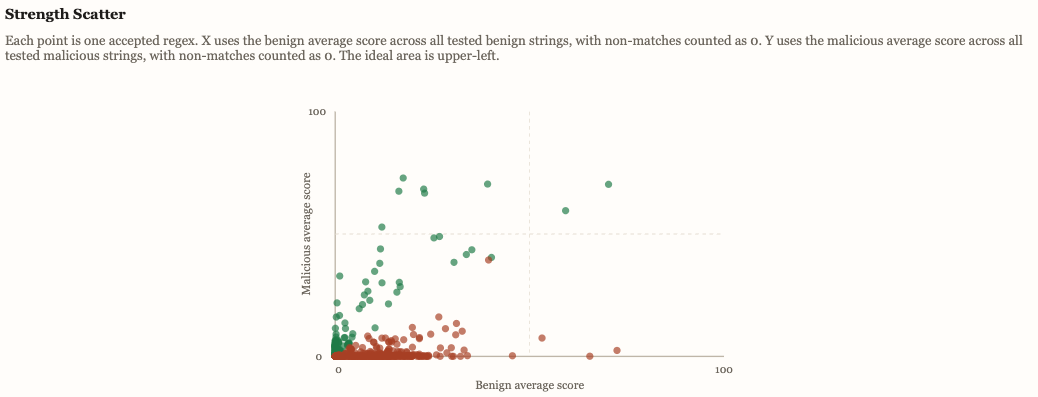
The RegexGenerator module was created to give Slips an adaptive way to discover new string-based detectors for changing indicators such as domains, URIs, filenames, TLS SNI values, and certificate common names. It continuously uses the shared LLM service to propose one regex at a time, then applies local validation and negative selection against benign corpora to reject unsafe or overly broad patterns. The accepted regexes become a reusable adaptive recognition repertoire for other modules, especially the T Cell responder.
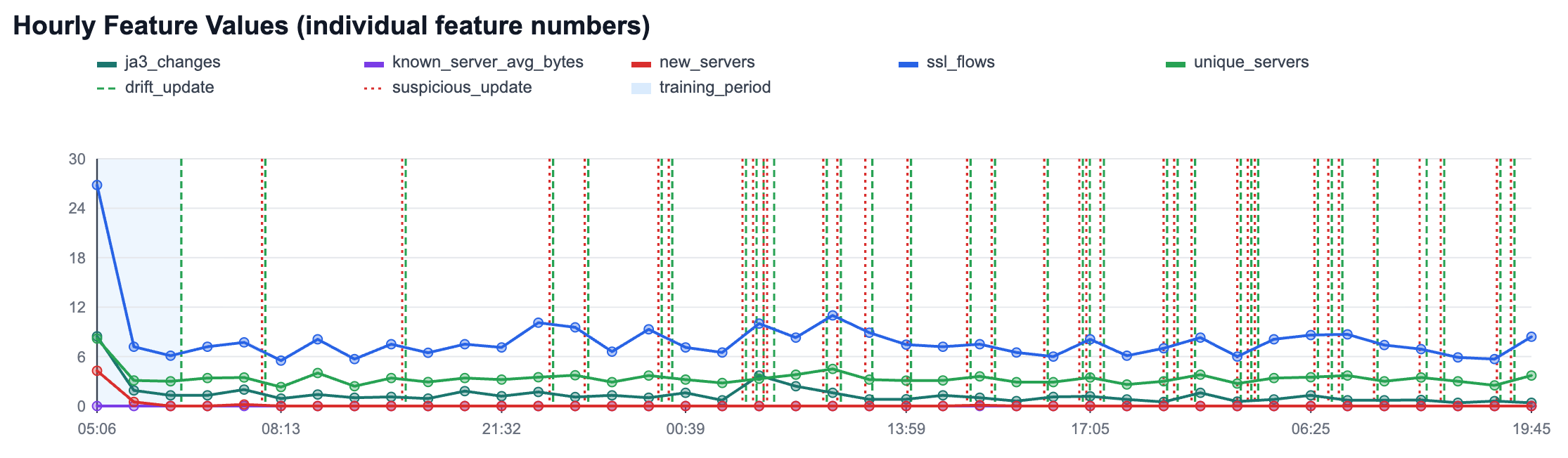
The new HTTPS anomaly detection module in Slips builds per-host adaptive baselines in traffic time, then detects deviations at two levels: per-flow (for bytes to known servers) and per-hour (for host behavior like new servers, unique servers, JA3 changes, and flow volume). It uses online statistics and z-scores for transparent scoring, plus controlled adaptation states (training_fit, drift_update, suspicious_update) to keep learning while reducing poisoning risk.
The result is explainable, operational evidence in clear human text: what changed, confidence, and why it is anomalous.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
Two years ago, we launched the “Introduction to Security” class as a Massive Open Online Course with one ambitious goal: to make high-quality, hands-on cybersecurity education free and accessible worldwide. The response has been really beyond anything we imagined.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
Small satellites are increasingly vulnerable to cyberattacks, yet their resource constraints make implementing robust security mechanisms a significant challenge. This thesis explores how to protect the integrity of satellite and payload data against malicious software running in orbit, a problem that has received limited attention in the satellite security research community.
Training classifiers for network intrusion detection is hindered by two types of problems: data challenges (lack of labels, class imbalance, non-IID data, and concept drift) and engineering challenges (memory & compute efficiency, data ingestion, parallel training, and hyperparameter optimization). Existing ad-hoc scripts make it hard to reproduce results or compare models systematically across these conditions. An extendable machine learning pipeline is developed to address both, targeting malicious network flow classifiers for the Stratosphere Linux IPS (Slips). The output is a set of best-performing models at different FPR and F1 thresholds suitable for deployment in Slips.
Sebastian has just been awarded by the Dean of the Faculty of Electrical Engineering, Czech Technical University in Prague, for his outstanding teaching performance in the Winter Semester 2025/2026!
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
NetSecGame v0.2.0 is here. This release focuses on what matters most for reproducible AI research: deterministic episode control, a more robust simulation server, and a significantly expanded test suite. Whether you are running large-scale RL experiments or debugging a new agent, v0.2.0 makes the process more reliable.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
The T Cell module was created to give Slips a stateful adaptive response layer on top of its existing evidence pipeline. While the original detectors already provide the innate immune component through PAMP and DAMP evidence, the T Cell module adds antigen recognition, co-stimulation, context evaluation, tolerance, activation, effector action, and memory. It does this by extracting structured antigens from live evidence, matching them against the accepted regex repertoire generated by RegexGenerator, and then combining that recognition with the cumulative danger signaled by recent PAMP and DAMP observations. This allows Slips to move from isolated detections to a more explicit immune decision process that can decide when to ignore, when to contain, and when to remember.
The RegexGenerator module was created to give Slips an adaptive way to discover new string-based detectors for changing indicators such as domains, URIs, filenames, TLS SNI values, and certificate common names. It continuously uses the shared LLM service to propose one regex at a time, then applies local validation and negative selection against benign corpora to reject unsafe or overly broad patterns. The accepted regexes become a reusable adaptive recognition repertoire for other modules, especially the T Cell responder.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
The new HTTPS anomaly detection module in Slips builds per-host adaptive baselines in traffic time, then detects deviations at two levels: per-flow (for bytes to known servers) and per-hour (for host behavior like new servers, unique servers, JA3 changes, and flow volume). It uses online statistics and z-scores for transparent scoring, plus controlled adaptation states (training_fit, drift_update, suspicious_update) to keep learning while reducing poisoning risk.
The result is explainable, operational evidence in clear human text: what changed, confidence, and why it is anomalous.
Our research identifies sixteen fundamental principles of biological immunity and translates them into cybersecurity defense architectures that emphasize multi-dimensional coordination over single- point tactics.
We are excited to announce the release of NetSecGame (NSG) v0.1.0, a framework for training and evaluating AI agents in network security environments. Developed at the Stratosphere Laboratory at CTU in Prague, NSG provides a highly configurable testbed for both offensive and defensive security tasks.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.
We are pleased to announce the publication of our latest paper, “Building adaptive and transparent cyber agents with local language models,” in the Journal of Expert Systems with Applications.
Our team is excited to share the latest news and features of Slips, our behavioral-based machine learning intrusion detection system.












