
This blog post was authored by Carlos Catania on May 27, 2025
Inference Engines Considered on Raspberry Pi 5
Several inference engines were evaluated for running language models efficiently on the Raspberry Pi 5. The key focus areas included CPU quantization support, inference speed, memory usage, and overall system stability under sustained workloads.
Ollama was used as the initial baseline. It supports CPU and GUFF quantization and provides a simple interface for deploying models. However, in comparative testing, llama.cppdemonstrated slightly better performance. Although it shares a common foundation with Ollama, llama.cpp delivered improved inference speeds and more efficient use of system resources. These advantages, combined with active community support, led to its selection as the preferred engine for further development.
Transformers from HuggingFace were also considered. Despite their popularity and flexibility, the lack of CPU quantization support made them impractical for the Raspberry Pi 5. Models were too large and slow for this constrained environment. Other engines built on similar foundations, such as vLLM solutions and frameworks like unsloth, faced similar limitations and were not pursued further.
An additional engine, bitnet.cpp, was tested for its innovative support of 1.58-bit quantization. It is tailored specifically for BitNet models, such as the bitnet-b1.58-2B-4T. This engine provides fast and lossless inference optimized for CPUs and GPUs. BitNet models demonstrated strong potential on the Raspberry Pi 5, achieving around 8 tokens per second (TPS) with a low memory footprint. However, broader adoption is limited by the current lack of available models and incomplete fine-tuning support.
The table below summarizes the characteristics of the main inference engines considered:
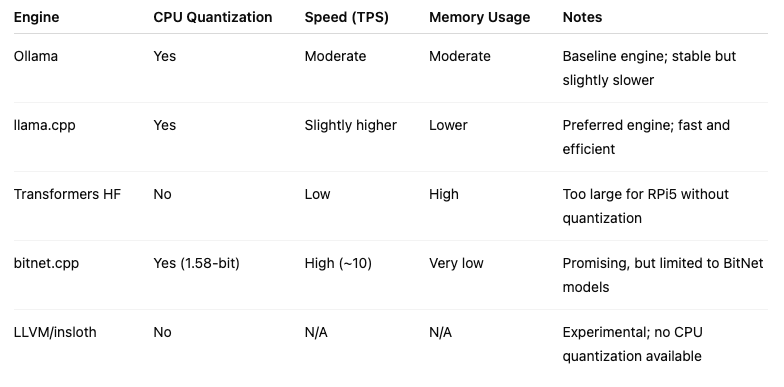
Table 1: A quick comparison of engines tested on the Raspberry Pi 5 for LLM performance, covering CPU quantization, speed, memory usage, and notes on suitability.
Ollama initially appeared to be the most balanced option, offering a good trade-off between performance, ease of management, and future upgradability. However, several limitations in its default configuration led to reconsideration. Since Ollama is under active development, many default settings are not optimized for low-resource environments like the Raspberry Pi 5. One major issue is that Ollama defaults to a context window of 4096 tokens for all models, regardless of their actual capabilities. This constraint can significantly limit performance on tasks requiring longer context lengths, and the discrepancy is only noticeable in runtime logs. To overcome this, the environment variable OLLAMA_CONTEXT_LENGTH must be manually configured to match the model’s maximum context.
Additionally, Ollama does not provide an intuitive way to control CPU thread usage. By default, it utilizes all four threads available on the Pi, which can be problematic when other lightweight background processes (such as system monitors or schedulers) need to run concurrently.
As a result, llama.cpp was chosen as the primary inference engine for current use. Although slightly more complex to configure, it offers full control over parameters such as context length, thread count, and memory allocation. Performance benchmarks also show llama.cpp is approximately 10% to 20% faster than Ollama. While these limitations in Ollama may be resolved in future updates, llama.cpp currently provides better performance and configurability, making it the most suitable choice for sustained deployment on the Raspberry Pi 5.
Performance on RPI
The performance analysis of LLMs on the Raspberry Pi 5 focuses on balancing limited hardware resources with the effectiveness of each model across various tasks. The goal is to identify models that offer the best trade-off between speed, memory usage, and task-specific accuracy within the constraints of the device.
System Resource Utilization
A set of evaluation scripts was developed to assess model performance on the Raspberry Pi 5. While the final deployment will use llama.cpp, all models were tested using the Ollama engine because it is simple to configure. The only exception was BitNet, which was tested using bitnet.cpp due to compatibility requirements.
The script reports the quantization method used by each model, the tokens per second for a simple prompt, and the memory footprint. It was executed on the Raspberry Pi 5, and the results are summarized in the following table.

Table 2: This table compares various LLM models tested on the Raspberry Pi 5, highlighting disk size, RAM usage, tokens per second performance, and quantization methods.
In summary, gemma3:1b stands out as the most efficient model, combining low resource usage with the highest token throughput, making it ideal for lightweight and responsive applications. Models like llama3.2:1b-instruct also perform well, offering strong speed-to-resource ratios. Overall, these models provide a good mix of efficiency and performance, allowing for flexible deployment depending on hardware constraints and task requirements.
Smaller models like gemma3:1b and qwen2.5:1.5b offer the best balance of speed and low resource usage. While 3B models like llama3.2:3b and qwen2.5:3b require more memory, Qwen models remain impressively efficient even at larger scales.
In contrast, smollm2:1.7b-instruct has a high memory footprint (over 5 GB), making it less ideal for limited-resource environments like the Rpi.
Finally, BitNet B1.58 2B 4T offers a good trade-off between memory footprint and tokens per second. Compared to other 2B models like granite, it has less than half the memory footprint while being approximately 1.5 times faster in token generation. The model is also competitive compared with models like qwen2.5:1.5b
Overall, the Qwen models stand out for their strong performance combined with excellent memory efficiency, and BitNet B1.58 2B 4T emerges as a strong contender in this space.
Task-Specific Performance evaluation
To evaluate task-specific performance, Promptfoo tests were replicated on the Raspberry Pi 5. Ollama was used as the baseline engine via its OpenAI-compatible API. To accommodate the limitations of the RPi5, specific environment variables were configured during execution.
Ollama Environment Variable Descriptions
OLLAMA_HOST=0.0.0.0:11434
Sets the network address and port the Ollama server will bind to.0.0.0.0listens on all available network interfaces.11434is the port number.
OLLAMA_MAX_LOADED_MODELS=1
Limits the number of models that can be loaded into memory simultaneously.
Helps conserve memory by restricting model concurrency.OLLAMA_MAX_QUEUE=2
Sets the maximum number of queued requests waiting to be processed.
Requests exceeding this limit may be delayed or rejected.OLLAMA_KEEP_ALIVE=0
Determines whether idle models remain loaded in memory.0disables keep-alive (unloads idle models). This setup was used for running the tests, because we found some issues with ollama automatic unloading.Another value, will save memory at the cost of reload time.
OLLAMA_DEBUG=1
Enables debug mode for more verbose logging.
Useful for development and troubleshooting troughjournalctl -f -b -u ollama`OLLAMA_LOAD_TIMEOUT=60m0s
Specifies the maximum amount of time to wait for a model to load.
Set to 60 minutes in this case, which is necessary because some models load very slowly on the Raspberry Pi. Without this extended timeout, tools like Promptfoo may prematurely terminate the connection.OLLAMA_CONTEXT_LENGTH=8192
Defines the maximum token context length that models can process. A length of8192 tokenssupports long-form prompts or conversations. By defaultollama` uses4096` in the Pi.
The results of the Promptfoo tests are presented in the heatmap below. In addition to the previously evaluated models, BitNet B1.58 2B 4T was included using 1.58-bit quantization with bitnet.cpp. Note that not all models are compatible with 1.58-bit quantization.
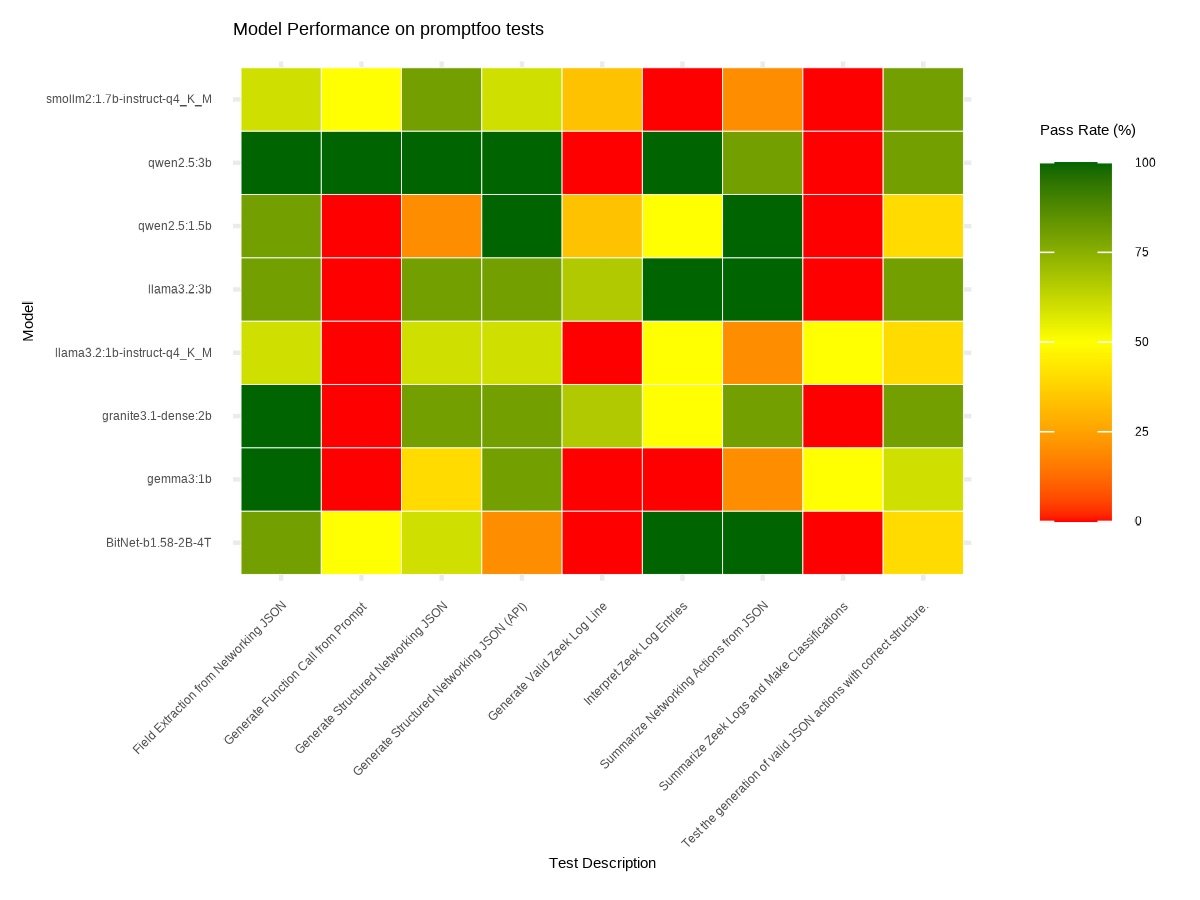
Figure 1: This heatmap compares the performance of different LLM models on the Raspberry Pi 5, highlighting their pass rates across various promptfoo tasks.
Results from Promptfoo on the Raspberry Pi 5 were consistent with those reported for x86 architecture.
The test involving the function calling failed in most of the considered models except BitNet B1.58 2B 4T and SmolLm2:1.7b.
The test involving the analysis of Zeek logs and performing classifications, failed across all models with 3B parameters, including Qwen2.5 3B. The failure is due to the test requiring the processing of a prompt of approximately 5000 tokens. At a generation rate of about 5 tokens per second, the test takes roughly 15 minutes to complete. Promptfoo, however, terminates the connection before the models can finish processing.
Per test Analysis
This analysis considers performance on a per-test basis, highlighting two key models: the overall best-performing model, and the best model capable of achieving at least 8 tokens per second. The goal is to identify viable alternatives depending on specific needs. In some cases, speed may be the priority, while in others, accuracy or depth of understanding may take precedence. The choice of model will depend on the nature and requirements of each test.
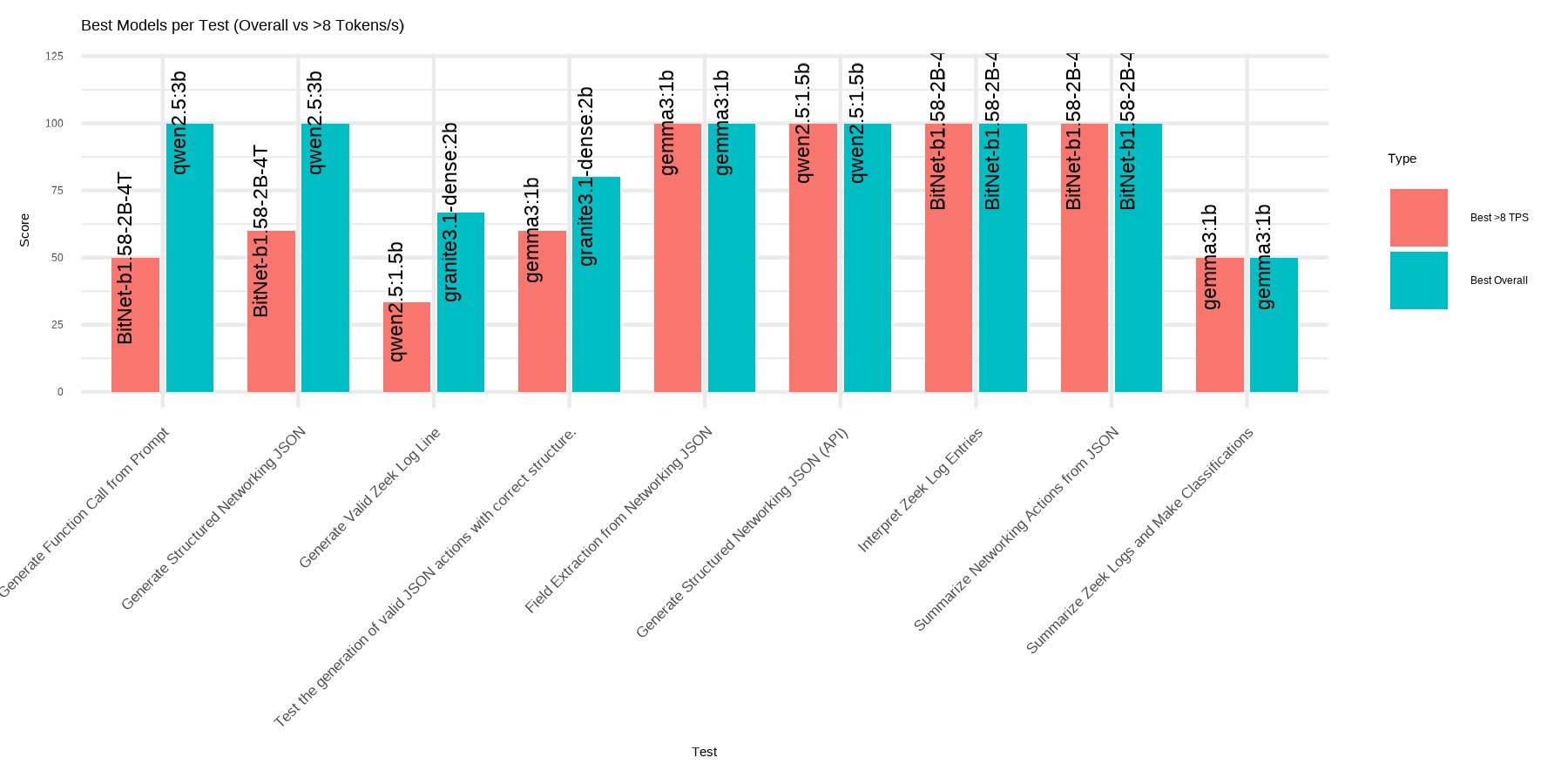
Figure 2: This bar chart shows the best-performing models for each promptfoo test on the Raspberry Pi 5, comparing overall best scores and best scores for models with speeds above 8 tokens per second (TPS).
Figure 2 shows that Qwen2 models consistently deliver the highest performance across most tasks, particularly in structured output scenarios like generating function calls or JSON data. However, when speed is a priority, BitNet B1.58 2B 4T emerges as a strong alternative, maintaining over 8 tokens per second while delivering reasonably competitive results. In tasks like interpreting or summarizing logs, Gemma and Granite3.1 also show up, but less frequently. The narrow performance gap in many cases suggests that faster models like BitNet B1.58 2B 4T can often be used without significant loss in accuracy, offering a practical trade-off between speed and precision depending on task demands.
Overall Score
To simplify the overall analysis, a single performance score was calculated for each model by averaging the results across all tests. These mean scores are presented in the figure below, providing a clear comparison of overall model performance.
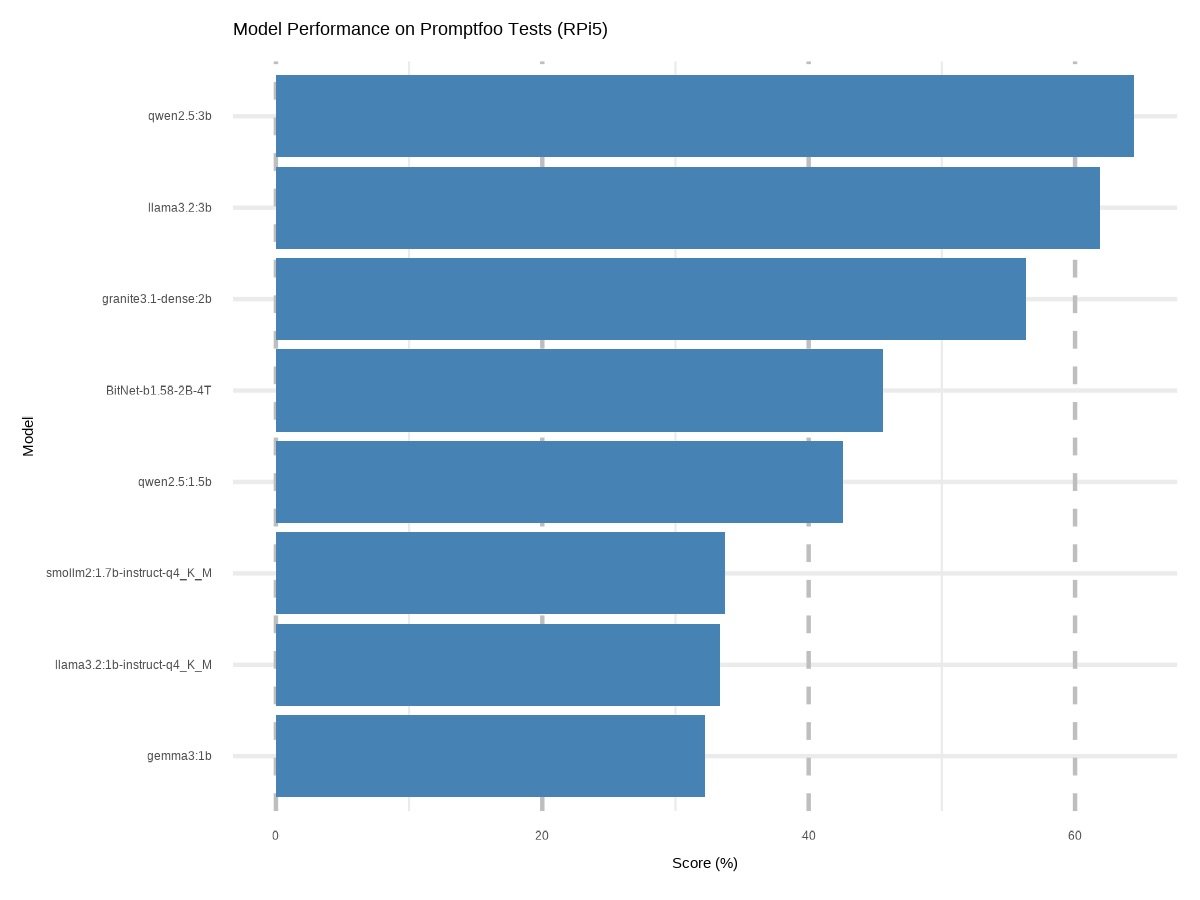
This bar chart illustrates the overall performance scores of various LLM models tested on the Raspberry Pi 5 using promptfoo tasks, highlighting their relative effectiveness.
As expected, the larger models such as LLaMA 3.2 3B and Qwen2.5 3B demonstrated the highest average score. These were followed by the 2B models, including Granite 3.1 Dense and BitNet B1.58 2B 4T, which also showed competitive results relative to their size.
Trade off analysis

Figure 4: This scatter plot shows the trade-off between performance scores and tokens-per-second (TPS) of different LLM models on the Raspberry Pi 5. Circle sizes represent RAM usage, highlighting the balance between performance and resource demands.
The figure below analyzes model performance using two key metrics: overall score and tokens per second. These highlight the balance between resource use and speed. Additionally, RAM usage is plotted to visualize each model’s memory footprint.
This review highlights the balance between performance, speed, and resource usage across various language models. Qwen2.5 models consistently lead in overall performance, especially in structured tasks, while maintaining good efficiency. In particular, qwen2.5:1.5b offers both high throughput and low memory consumption, making it a strong all-around choice. Gemma3:1b-instruct also shows solid efficiency, making it suitable for lightweight deployments.
BitNet B1.58 2B 4T stands out for its exceptional memory efficiency, achieving over 8 tokens per second with one of the smallest RAM footprints. This makes it well-suited for environments with limited resources. In contrast, Smollm2:1.7b-instruct delivers reasonable performance but requires significantly more memory, which can limit its usability.
Overall, Qwen models dominate in balanced performance. BitNet is ideal for fast, low-resource scenarios. The best model choice depends on the specific needs of each task, with some favoring speed and others requiring greater accuracy or capability.
Finals remarks
Llama.cpp was chosen as the primary inference engine for production use. Although it requires a more complex setup, it provides full control over key parameters such as context length, thread count, and memory allocation. Ollama will continue to be used during development and testing due to its simplicity in managing models, but llama.cpp will be preferred for deployment.
Qwen models stand out as the most effective overall. The 3B version consistently achieves the highest average scores, making it ideal for tasks that prioritize accuracy. The 1.5B version offers a strong balance between performance and speed, while maintaining a relatively low memory footprint. Rather than relying on a single model for all tasks, the strategy is to adapt model selection based on specific requirements. The combination of Qwen 3B and 1.5B allows for flexibility in choosing between higher accuracy and better efficiency as needed.
BitNet models also show promise, especially in terms of speed and memory efficiency. However, the lack of a clear fine-tuning path limits their current utility. They will continue to be monitored, but for now, Qwen models remain the preferred choice for both versatility and reliability.
References
[1] Scripts for testing hardware resources in Rpi5
[2] Promptfoo tests