Network defenders often face a practical contradiction: HTTPS is where critical business traffic lives, but it is also where modern malware hides. Static signatures and one-shot thresholds rarely survive contact with real enterprise behavior. User activity changes by hour, hosts age, software updates shift fingerprints, and traffic can be processed live or replayed from old PCAPs.
The new anomaly_detection_https module in Slips is built to handle that reality.
This post explains the module end-to-end: goals, feature engineering, statistical modeling, confidence scoring, adaptation strategy, evidence generation, and why each design decision was made.
Why this module exists
The goal is not to classify “malware family X” directly. The goal is to detect behavioral deviations in HTTPS usage per host with low operational friction:
- Work with live interfaces, live Zeek folders, PCAPs, and Zeek files.
- The user can specify a start bening training time, so the model can learn, but it can also be run with
training_hours = 0to force inmediate operation. - Adapt automatically while reducing poisoning risk.
- Produce evidence readable by humans and usable by downstream systems.
The module treats each host independently. Baselines are never global across all hosts.
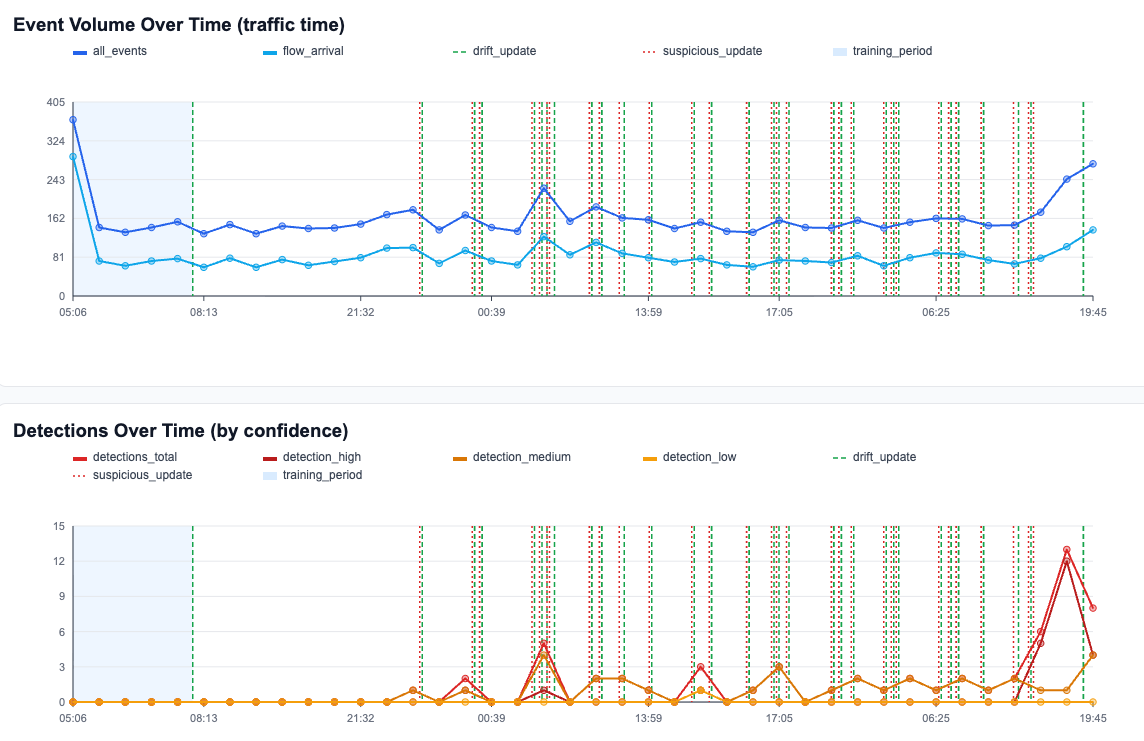
Data pipeline and correlation
The detector is triggered by SSL/TLS Zeek flows. For each SSL event it also retrieves related metadata from its corresponding general flows from the Slips DB to get transport context and bytes.
Core signals consumed:
- SSL/TLS:
uid,server_name(SNI),ja3,ja3s, ports. - General flow correlation: destination IP, bytes, timing, 5-tuple context.
This produces two levels of detection:
- Flow-level checks (per SSL event).
- Hourly host-level checks (aggregated behavior in one-hour buckets).
Time semantics: traffic time first
A major design decision is strict use of traffic timestamps for model logic:
- Hour buckets are based on packet/log timestamps.
- Training completion is measured in traffic hours.
- Drift and suspicious updates happen on traffic-hour boundaries.
This avoids distortions when replaying old captures fast, pausing, or processing out of real-time.
Feature set
The model combines novelty and magnitude features.
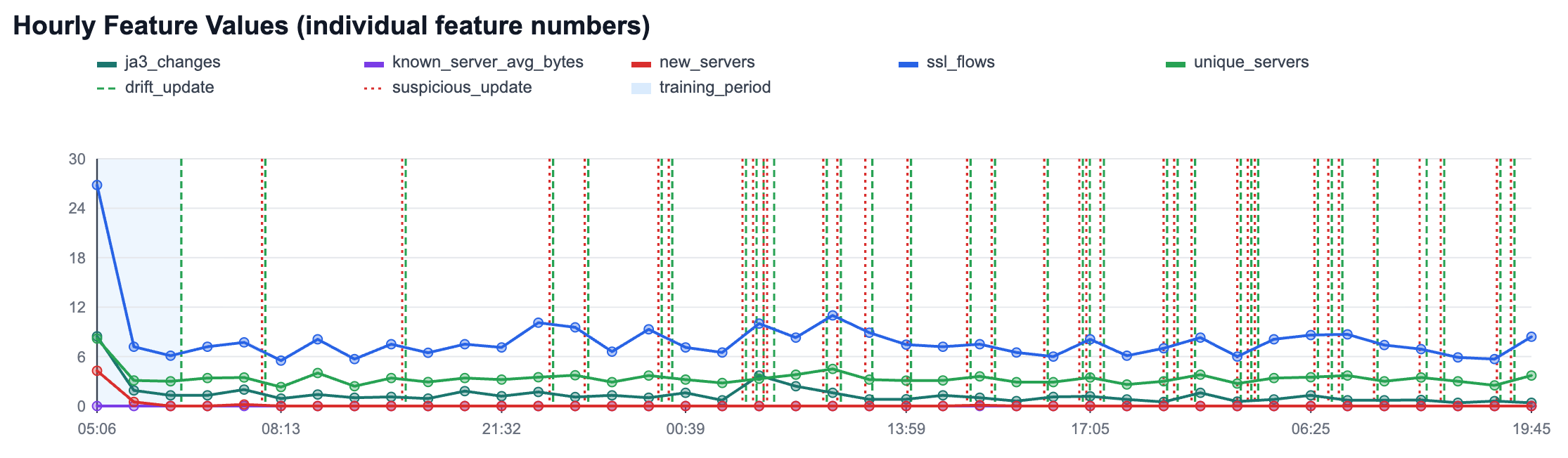
Hourly features at the src host-level
For each src host and each traffic hour:
ssl_flows: number of SSL flows.unique_servers: number of distinct servers contacted.new_servers: number of first-seen servers for this host.ja3_changes: number of new JA3 variants per server observed in the hour.known_server_avg_bytes: average bytes for flows to already-known servers.
Flow-level feature at the dst server-level
bytes_to_known_server: bytes anomaly for a flow to a known server.
This captures three practical infection indicators:
- New remote infrastructure patterns.
- Sudden changes in endpoint/client TLS behavior.
- Volume shifts against known destinations.
Statistical model
Each modeled signal uses online moments and z-score detection.
Online moments
For a feature value stream (x_t), the module maintains per-host (and for bytes, per-server) summary statistics:
Mean $$mu_t$$
Variance $$sigma_t^2$$
Count $$n_t$$
During benign training it uses Welford-style updates (stable online mean/variance estimation).
Detection score
Anomaly magnitude is measured with z-score:
$$z_t = \frac{|x_t - \mu_t|}{\max(\sigma_t, \sigma_{\min})}$$
where ($$\sigma_{\min}$$) is a robust minimum std floor to avoid unstable huge scores when variance is near zero.
Detection rules:
- Hourly feature anomaly if ($$z_t \ge \texttt{hourly_zscore_threshold}$$)
- Flow bytes anomaly if ($$z_t \ge \texttt{flow_zscore_threshold}$$)
Training modes
1) Explicit benign training (training_hours > 0)
For the first configured traffic hours, data is treated as benign baseline fit:
- Models are fitted strongly.
- Hourly z-score detections are not used for baseline decisions.
- Baseline quality rises quickly as points accumulate.
This mode is for environments where the first N hours are trusted.
2) Zero-hour start (training_hours = 0)
The module starts detecting immediately while learning online.
A specific guard is used for early JA3 volatility:
ja3_changeshourly signal can be gated until reachingja3_min_variants_per_server(fallback behavior for no-training mode).
This reduces startup noise when no curated benign period is available.
Adaptation strategy: learn, but do not get poisoned
After each hourly window closes, the module decides how aggressively to update the baseline.
Let:
hourly_score= sum of hourly z-scores that crossed threshold.flow_anomaly_count= number of flow-level anomalies in that hour.
State A: training_fit
If still in benign training period:
- Update with training fit (Welford), not EWMA alpha.
State B: drift_update
If anomalies are small:
hourly_score <= adaptation_score_thresholdflow_anomaly_count <= max_small_flow_anomalies
Then treat as benign drift and update with drift_alpha.
State C: suspicious_update
Otherwise:
- Update with much smaller
suspicious_alpha.
This still allows slow adaptation (important for long runs), but limits rapid model poisoning during suspicious periods.
For clean non-anomalous operation outside training, normal adaptation uses baseline_alpha.
Confidence model
Every detection gets a confidence score in ([0,1]), then a confidence level (low/medium/high).
The score blends multiple factors:
- Severity (how strong are anomaly signals, including z-scores)
- Persistence (recent anomaly continuity)
- Baseline quality (how reliable the learned model is)
- Multi-signal agreement (single weak reason vs multiple supporting reasons)
This avoids naive confidence definitions and produces more stable triage behavior.
Threat level mapping in emitted evidence:
lowconfidence -> threatlowmediumconfidence -> threatlowhighconfidence -> threatmedium
Evidence generation: human-first descriptions
Evidence descriptions are now plain text, concise, and operational:
HTTPS anomaly: type=<type>; confidence=<level> (<score>); reason=<reason>; value=<value>; why=<explanation>.
Examples of reasons:
- New Server
- New JA3S
- Bytes to Known Server
- Hourly deviations like New Servers Count or JA3 Changes
The source IP is already part of the evidence object, so it is not repeated in the description body.
Operational observability
The module logs key lifecycle events with structured metrics:
- flow arrival and correlation context,
- hourly bucket close and computed features,
- model update mode (
training_fit,drift_update,suspicious_update), - alpha used for each update,
- detection reasons and confidence factors,
- evidence emission.
This makes the detector explainable during troubleshooting and tuning.
Why these design choices
- Per-host modeling: avoids blending unrelated behavior across machines.
- Traffic-time windows: works consistently in live and offline modes.
- Hybrid flow+hour detection: catches both spikes and pattern shifts.
- Online stats + z-score: simple, interpretable, cheap at runtime.
- Adaptive update states: keeps learning while resisting poisoning.
- Human-readable evidence: easier analyst triage and auditability.
Configuration knobs that matter most
In config/slips.yaml (anomaly_detection_https section):
training_hourshourly_zscore_thresholdflow_zscore_thresholdadaptation_score_thresholdbaseline_alphadrift_alphasuspicious_alphamin_baseline_pointsmax_small_flow_anomaliesja3_min_variants_per_serverlog_verbosity
Practical tuning rule:
- If false positives are high after trusted training, first increase z-score thresholds slightly and/or reduce adaptation aggressiveness.
- If adaptation is too slow in stable environments, increase
baseline_alphacarefully.
Closing note
This module is designed as a production-oriented anomaly detector: statistically grounded, explainable, adaptive, and compatible with the real operational constraints of network telemetry.
It does not rely on a fragile single indicator. It combines novelty, distribution shifts, per-host baselines, and controlled adaptation to surface HTTPS anomalies that are both detectable and actionable.