Network threats do not arrive as one fixed string that can be hard-coded once and forgotten. Domains vary, URIs mutate, filenames drift, TLS SNI values change, and certificate names are reused in slightly different forms. A system that only depends on exact literals or hand-written pattern updates is always reacting after the fact.
That is one of the reasons Slips is moving toward immunology concepts. The old detector structure is already a strong innate immune system: it produces broad evidence quickly from many traffic sources. What was missing was an adaptive way to keep building new candidate recognizers continuously.
RegexGenerator fills that gap. It gives
Slips a mechanism to
continually propose, evaluate, reject, and retain regex-based receptors instead
of waiting for every new pattern to be manually engineered.
Instead of hard-coding every future pattern in advance, Slips can now pseudo-generate candidate regex detectors, validate them locally, reject the dangerous or overly broad ones, and keep only the candidates that survive a negative-selection step against benign data.
That is the role of:
modules/regex_generator/regex_generator.py
This module is one of the adaptive building blocks of the immune design in Slips. It is the part that keeps building candidate receptors in the background so the adaptive layer always has new hypotheses to test.
Why Generate Regexes Continually?
Many relevant indicators in network evidence are not just IP addresses. They are structured strings:
- domains
- URIs
- filenames
- TLS SNI values
- certificate common names
These strings often carry strong semantic information, but they also vary heavily. A hard-coded exact match is often too narrow, while a naive wildcard regex is often too broad.
The idea behind RegexGenerator is to explore that middle ground:
- generate candidate symbolic detectors
- keep them narrow enough to avoid matching benign traffic
- make them reusable by other modules
The result is a growing local repertoire of candidate recognizers that can be
queried later by modules such as T Cell.
Just as important, this is not a one-shot batch job. The module runs
continuously. As long as Slips is running, RegexGenerator keeps asking for a
new candidate, evaluating it, and either rejecting it or adding it to the
accepted receptor pool.
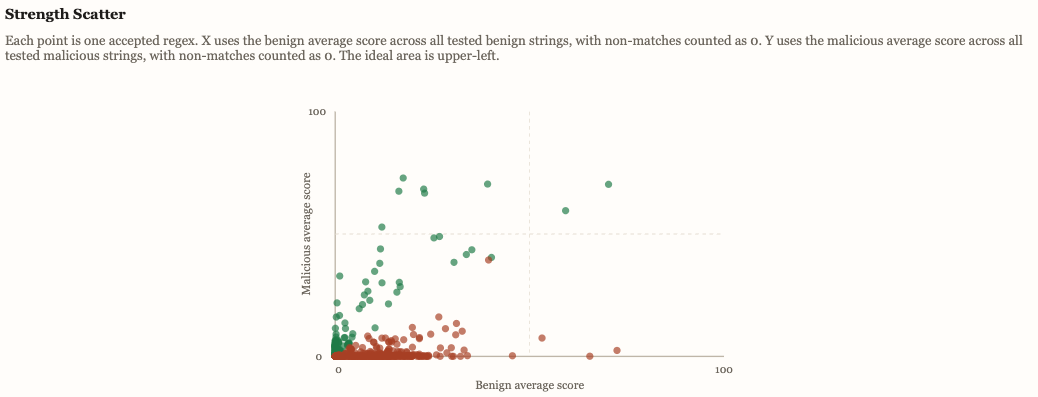
The resulting repertoire is not opaque. The offline coverage report lets us inspect how many accepted regexes exist per type, how they score against reference populations, and how much benign spillover remains:

Why "Pseudo-Generated" and Not Just "Generated"?
The regexes are not accepted directly from the LLM.
The LLM is used only as a hypothesis generator. It proposes one candidate regex at a time. Slips then does the actual engineering work locally:
- parse the reply
- validate syntax and safety
- reject obvious bad constructions
- compare the candidate against benign data
- store only accepted regexes
So the regex is pseudo-generated in the sense that the creative step comes from the model, but acceptance is determined by Slips itself.
This distinction matters. The module is not trusting model output as if it were ground truth. It is treating it as a candidate detector that must pass selection.
Using the Shared LLM Module
RegexGenerator does not talk to one specific model API directly. It uses the
new shared LLM module in Slips over the Redis channels:
llm_requestllm_response
That means Slips can take advantage of modern AI models without baking one provider into the regex logic itself.
The shared LLM layer decides how to talk to the configured backend. The regex module just says:
- I need one candidate regex
- for this exact regex type
- with this request ID
This separation is important because it keeps the adaptive detector logic independent from the transport and backend details of the LLM itself.
Why the Prompting Matters
The prompt design is intentionally strict.
The module does not ask the model for an explanation, JSON, or a list of options. It asks for exactly one raw regex line for one exact regex type.
It also sends a fresh generation nonce with every request. Combined with the type-specific prompt, that nudges the model away from repeating the same answer and toward producing a new candidate each cycle.
So the system is not just "calling an LLM." It is using constrained prompting to turn the model into a continual hypothesis generator:
- one regex at a time
- for one target type at a time
- with a fresh nonce at every generation cycle
That prompting strategy is then backed by local duplicate checks, local syntax validation, and negative selection, so the model is encouraged to produce novelty but Slips remains responsible for acceptance.
Five Supported Regex Types
The module currently generates regexes for five structured data types:
dns_domainurifilenametls_snicertificate_cn
These types were chosen because they are stable, meaningful, and already show up naturally in Slips evidence and linked altflows.
That means the adaptive layer is not inventing arbitrary string targets. It is working on fields that already matter operationally:
- DNS query names and HTTP hosts
- HTTP request URIs
- filenames derived from HTTP paths
- TLS Server Name Indication values
- certificate Common Name values
The same five types are also what later let the T Cell module do adaptive
antigen recognition.
How a Regex Candidate Is Created
Each cycle of RegexGenerator is intentionally small and controlled.
The module:
- chooses one regex type
- selects an available LLM backend through the shared
LLMservice - sends a minimal typed prompt asking for exactly one regex
- waits for the matching response by
request_id - extracts a single regex line from the reply
Only one request is in flight at a time. That keeps response correlation simple and makes the continual generation process easy to audit.
This is not bulk generation. It is a continuous stream of one candidate at a time, because each candidate still has to pass a local selection pipeline.
Local Validation Before Selection
Before the module even compares a regex against benign data, it runs a static safety gate.
Candidates are rejected if they are malformed or operationally unsafe, for example:
- non-ASCII patterns
- invalid syntax
- excessive length
- lookbehind
- backreferences
- obviously broad expressions such as
.*or.+ - unbounded prefix/suffix wildcard structures
- nested wildcard constructions that risk catastrophic backtracking
This step is important because it prevents the selection stage from wasting time on candidates that are clearly unacceptable for runtime use.
Negative Selection Against Benign Traffic
This is the core of the module.
In immunology, negative selection removes detectors that react to what should be tolerated. In Slips, that means candidate regexes are tested against a benign corpus and rejected if they match benign strings too strongly.
The module does not reject on any benign hit. That would be too strict. Instead, it computes a benign match-strength score and rejects only when a benign string crosses a configured threshold.
That score considers:
- how much of the benign string was covered
- whether the match starts at the beginning
- whether the match reaches the end
- whether it is a full-string match
- how literal or specific the regex looks
- how much wildcard power the regex uses
So the selection rule is more nuanced than "matched something benign, reject it." A candidate can survive weak or partial benign overlap while still being rejected if it behaves like a broad general-purpose pattern.
This is the operational negative selection algorithm in Slips:
- generate a candidate receptor
- expose it to benign data of the same type
- reject it if it reacts too strongly to benign strings
- keep it only if it stays below the benign threshold
That is what turns free-form generation into a tolerized detector-building process.
What Counts as the Benign Corpus?
The benign corpus is not a single static file.
The module can populate it from several sources:
- a small built-in seed sample
- the local Slips whitelist
- the ordered top Tranco domains already cached by Slips
- data directly from Slips traffic, if in the last time windows there were no anomalies or detections.
That last source is especially useful. When a time window from the local host closes with zero alerts and zero evidence, the module can treat those observed strings as clean operational context and import them into the benign corpus.
This means the negative selection process is not only generic. It can adapt to the real environment where Slips is running.
In practice, that helps prevent the adaptive layer from learning detectors that would constantly fire on the local normal baseline.
Duplicate Control and Storage
The module also avoids wasting effort on repeated candidates.
It uses:
- bloom filters
- exact SQLite lookup
to suppress cheap repeats and keep the accepted set cleaner over time.
Accepted regexes are stored in:
<run_output_dir>/regex_generator/generated_regexes.sqlite
Rejected regexes can be persisted too, but by default they are not written to disk. That keeps the main store focused on the useful adaptive repertoire.
The stored accepted regexes are then available through the DB helpers for other modules.
Why This Matters for the Immune Design
RegexGenerator is not just a regex toy. It is the adaptive receptor factory
for the larger immune model in Slips.
The existing Slips detectors produce the innate evidence layer:
- fast
- broad
- always on
But innate evidence alone does not create a reusable symbolic receptor repertoire.
That is what RegexGenerator provides:
- a growing set of validated candidate recognizers
- scoped to structured string fields
- filtered by negative selection
- reusable by later modules
Without this module, the adaptive layer would have no detector library to consult.
The Connection to T Cell
The clearest consumer of these accepted regexes is the T Cell module.
When T Cell receives PAMP evidence, it extracts structured antigens such as
domains, URIs, filenames, SNI values, and certificate CNs. It then queries the
accepted regex repertoire built by RegexGenerator.
That connection is the key architectural link:
RegexGeneratorbuilds candidate receptorsT Celluses those receptors on live evidence
So RegexGenerator is not making alerts by itself. It is preparing the
adaptive recognition layer that later allows T cells to say:
- this antigen looks recognizable
- this recognizable thing is or is not dangerous in context
What Makes This Different from Plain IOC Matching?
A normal IOC list gives exact values.
RegexGenerator creates pattern detectors that can generalize within bounds.
That lets Slips work with suspicious neighborhoods of strings instead of only
exact literals.
But that extra expressive power is also risky. A bad regex can easily become a false-positive machine.
That is why the negative-selection step is the real heart of the module.
The important idea is not "LLM-generated regexes."
The important idea is:
- candidate regexes are cheap to propose
- acceptance is expensive and local
- only the selected ones become part of the adaptive repertoire
That is a much safer and more defensible engineering design.
In Short
The RegexGenerator module gives Slips an adaptive receptor-building process.
It does that by:
- generating one regex candidate at a time
- working across five meaningful network-data types
- validating candidates locally
- applying a negative-selection algorithm against benign corpora
- storing only accepted regexes for later reuse
That makes it the first half of the adaptive immune system in Slips.
The second half is T Cell, which consumes those receptors during live
decision-making.