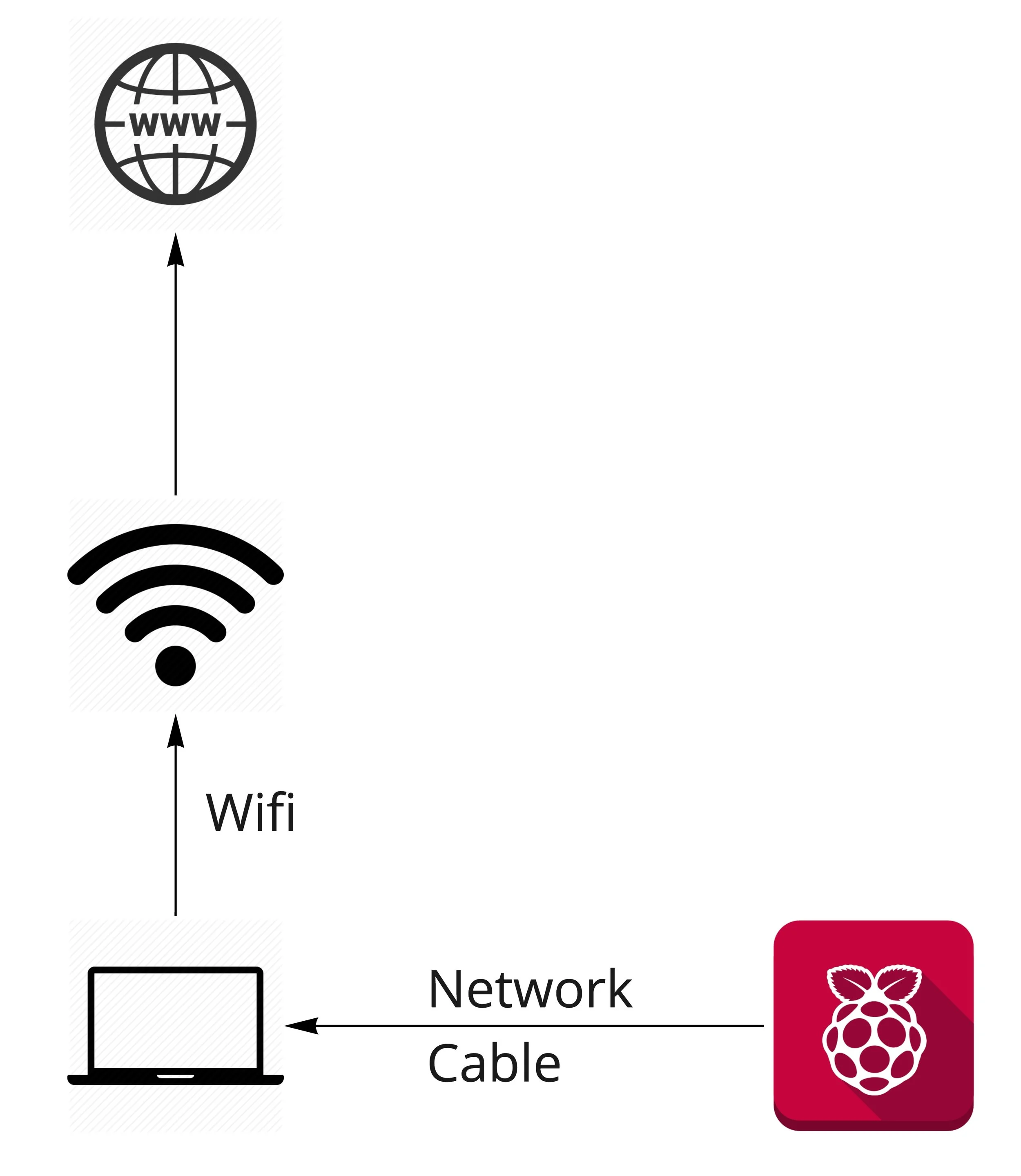
Working as security researchers is common to create a new machine learning algorithm that we want to evaluate. It may be that we are trying to detect malware, identify attacks or analyze IDS logs, but at some point we figure it out that we need a good dataset to complete our task. But not any dataset; in fact we need a labeled dataset. The dataset will be used not only to learn the features of, for example, malware traffic, but also to verify how good our algorithm is. Since getting a dataset is difficult and time consuming, the most common solution is to get a third-party dataset; although some researchers with time and resources may create their own. Either way, most usually we obtain a dataset of malware traffic (continuing with the malware traffic detection example) and we assign the label Malware to all of its instances. This looks good, so we make our training and testing, we obtain results and we publish. However, there are important problems in this approach that can jeopardize the results of our algorithm and the verification process. Let’s analyze each problem in turn.